Introducing the NYC Directory Project
Posted on Sun 12 June 2016 in posts
The NYC Directory Project uses Python to extract data from nineteenth-century address directories that have been scanned and made publicly available on Hathitrust.org. The final result will be a demographic and geocoded dataset that can be searched and analyzed to learn more about the residents of New York City in the 1800s.
Browsing through directories on Hathitrust and at the New York Public Library and other sites, I was intrigued at the sheer quantity of data embedded there and struck by what could be learned and accomplished by using code to clean and structure it. Historical sources such as the United States Federal Census and the New York State Census provide a useful picture of past New York City residents, but census data exists, at best, only at five-year intervals and prior to 1850, the census is notably vague.
Address directories have long been an alternative source of information for historians and genealogists. The scanning of address directories by Google, Archive.org, and others made them widely available so that getting access to them no longer required a physical trip to the repository that owned them. Even in digital format, however, they remained stubbornly analog, used primarily for locating individuals whose names were already known in an alphabetical index--just as originally intended. The production of text versions using OCR (optical character recognition) freed the directories from the tyranny of alphabetical order and made it possible to search the text by name, street, or occupation, for example.
Unfortunately, even with OCR, the utility of the address directories remains limited. You can text-search them, but you can't analyze them, and the inconsistent quality of OCR makes searching the directories a game of “hit or miss.” For example, in the image below, portions of the text were converted to cyrillic (anyone doing a text search for "Leedom, Widdifield & Cohn" is out of luck). In addition, the left and right columns ran together which will make parsing these address entries a special challenge.

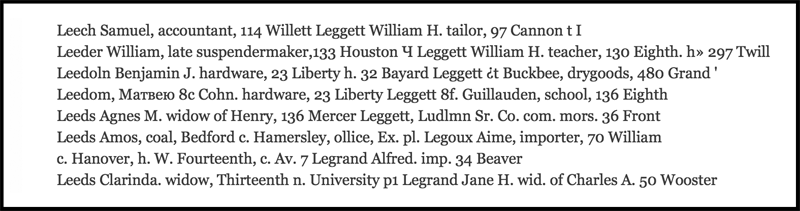
The NYC Directory Project is an effort to enhance the value of historical address directories by using Python to access, clean, and structure the text, and by using statistical inference to identify different address formats and to fix OCR errors where possible. This process will make searching a single directory considerably more effective, but more importantly it will allow for the systematic analysis of data within and across address directories, providing an annual snapshot of New York City as it was (or at least, as it appeared in these directories; as I will discuss in a future post, the directories were far from a comprehensive accounting of the city’s population). And because address directories, happily, used fairly consistent formats, this project is portable: the same code--with the inevitable tweaking--can be used to unlock the past of other cities as well.
While this project contributes to a larger effort by Historiscope to extract and disseminate demographically meaningful data from publicly available digitized documents, it's also inspired by some personal goals. I began this project in part as a means to learn and practice writing Python code, a tool I just recently added to my wheelhouse. I welcome and encourage suggestions and corrections.
Also, somewhere in those directories are the friends and relatives of my elusive ancestor William Peck Sims, a New York City wheelwright born around 1810 and a lifelong resident of old New York. Using the Python-enhanced version of these directories, I hope to get to know him and his world a little better.
